
精度实时表情捕捉!?FACEGOOD公开高精实时面捕DFCN论文
长期以来高精度实时表情捕捉一直没有理想算法,CubicMotion为数字人siren定制的算法需要大量时间做人工对齐,在实际生产中很难使用,苹果的Arkit简单易用但是由于天花板比较低,仅有52个变形体,导致表情丰富度较低。近日,FACEGOOD发表了一篇论文“High-Quality Real Time Facial Capture Based on Single Camera”实现了单目摄像头高精度实时表情捕捉,论文实验结果来看,FACEGOOD团队基于离线动画数据训练了一个神经网络用于驱动完整的Metahuman绑定,也就是直接驱动600+个变形体,是Arkit的十倍有余,实时表情捕捉的效果跟离线效果相近,实现了高精度捕捉,以下是论文内容。
摘要
我们提出了一个实时的基于视频的高精度实时表情捕捉框架蒸馏面部捕网络(Distill Facial Capture Network, DFCN)。我们的DFCN基于卷积神经网络利用大量视频数据来训练模型,最终产生高质量的连续的blendshape的权值输出。DFCN是自动的,因此可以大幅减少人工干预。我们在眼睛和嘴唇等挑战性大的部位展现了绝佳的仿真推理效果,尤其在语速较快的场合、在人脸微表情重建有很好的实现,我们实验结果证明,舌头可以随着嘴型同步运动,在面向不同绑定系统上也做到了很好的适配性。
1、引言
能够捕捉人脸的表情,并驱动虚拟的数字人表演出相同的表情,一直是计算机科学和图形学的热门研究话题。《阿凡达》的全球电影票房接近30亿美元,所谓前无古人,后无来者。阿凡达是名副其实的史上最受欢迎的虚拟偶像。每帧画面平均耗时四万个工时。演员表演时会佩戴一种头盔,实时捕捉脸部的肌肉数据,与计算机内绑定好的模型相匹配。这正是面部表情仿真系统的魅力所在。
纵观表情捕捉算法的发展史,面部表情捕捉技术主要分为关键点(landmark)驱动、点云(point cloud)驱动、声音驱动、基于图像和3D摄像头的。基于3D摄像头的缺点是:计算时间长,设备昂贵,没有捕捉眼球的表现。同样,各种声音驱动方法也没有分析眼球运动。但我们的蒸馏面部捕网络(Distill Facial Capture Network, DFCN)涉及眼球的表现。很多其他算法是基于模型的,而我们是基于图像的。在回归算法中引入知识蒸馏,提高了小网络的表达能力。
本文的突出贡献可以概括为:
1. 提出了一种基于视频序列的人脸实时捕获框架,用于blendshape权重和 2d landmark建立。
2. 提出了一种自适应回归蒸馏(Adaptive Regression Distill ,ARD)框架,该框架可以保证学生网络在去除异常值的数据上训练,并让小网络达到接近大网络的拟合能力。
2、问题的公式化
使用红外摄像机对抗光照影响。
公式(1)展现了3d面部网F由blendshapes的权重的线性组合生成,B = [b0, b1,…,bn],所有权重之和为1,并且单个权重也位于0到1之间。e是表情协方差,e = [e0,e1,…en]。
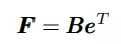 (1)
(1)
我们采用的blendshape模型是苹果公司提出的ArKit,其中包含52个动作单元(即,n = 52),模拟面部肌肉群的联合激活效应。我们的DFCN可以用这个公式(2)表示:
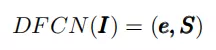 (2)
(2)
其中,I表示输入的图像,S表示2d面部形状,由所有2d landmarks sk组成。e是表情协方差。
3、蒸馏面部捕网络(Distill Facial Capture Network, DFCN)
在本节中,直接根据普通图像获取对应的blendshape和2d landmark的权重,我们提出了DFCN算法,该算法能够抵抗外界不同光照和抖动的影响。并使用一个端到端的方法获取blendshape权重。并且提出了一个混合滤波器来对抗帧与帧之间的不连续性。
我们使用了基于一组blendshape meshes的动态表情模型(Dynamic Expression Model, DEM)
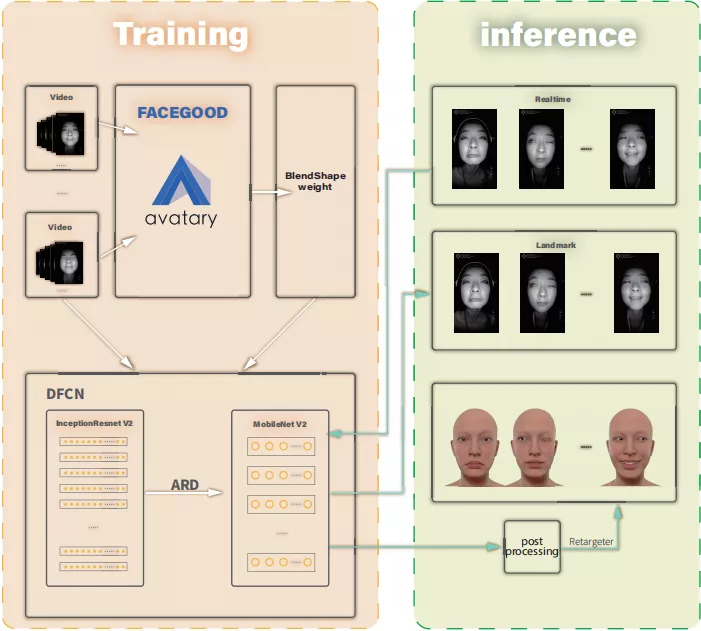
图一展示了我们的框架,包括模型训练和推理两个阶段。
可以大量节省劳动密集型生产级流程中的人工干预。
3.1、网络结构
从相机中获取1920 × 1080分辨率的视频,然后将每一帧转化为160 × 160分辨率的图片。所以,一共有25600个标量被送入神经网络。由于大网络的训练时间非常长,动辄一个月,而小网络的拟合能力又非常差,所以这里使用蒸馏来做模型压缩。老师网络是InceptionResNetv2,学生网络是MobileNetv2。
3.2、后处理
我们的混合滤波器主要采用的是Kalman滤波器和Savitzky-Golay(SG)滤波器。可以有效的减少帧与帧之间的数据抖动,对于landmark和blendshape权值数据都有可观的平滑效果。
3.3、训练
3.3.1、数据获取

FACEGOOD P1 helmet

图二展示的是演员需要佩戴的FACEGOOD P1头盔,前方配有一个摄像头用于实施捕捉演员的表情变化。该头盔非常轻,不会给佩戴者造成任何不适,且可以提供私人定制服务。且该头盔获取的视频数据可以降低光照的影响。
训练集需要包括下面四种数据:
标准的表情:先让演员做出一些极限位置的表情。比如:尽可能张开嘴巴,尽可能将下颚侧向和向前移动,撅起嘴唇,睁大眼睛然后强迫闭上。这样是为了捕捉到最大的面部动作。同时也需要一些正常的面部表情,如眯着眼睛或厌恶的表情。夸张表情和正常表情都必须包含在训练集中,否则神经网络将无法识别它们。
特殊的表情:这个数据集是演员们全力扭曲的表情,这样神经网络才能更好地学习到这些夸张的表情。
正常说话:这个数据集利用了一个事实,即演员对角色的表演通常在情感和表达范围方面存在严重偏见。演员可能会有符合角色设定的台词,以确保经过训练的网络产生符合角色的输出。
夸张说话:这一数据集记录着演员在说话时可能达到的最夸张的程度。
第二步:由FACEGOOD公司研发的Avatary软件将会根据这些视频数据集产生blendshape权重输出。
3.3.2、数据增强
图三可以看到:这里的数据增强是指改变光照强度,添加遮挡。可以让神经网络在推理时可以抵抗各种环境因素(如光照和遮挡)的影响,获得更好的鲁棒性。在CPU上对图像的变换,和在GPU上的网络训练和评估是同一时间进行的。

图三 数据增强
3.3.3、训练参数
我们使用Adam[Kingma and Ba, 2014]优化算法对教师网络进行400个epoches的训练。在第一个训练阶段,学习速率alpha以几何级数递增,然后递减。在最后60个epoches,使用平滑曲线将学习率降至零,同时将Adam β1参数从0.9降至0.5。ramp-up消除了网络不开始学习的隐患,ramp-down确保网络收敛到局部最小值。Minibatch size设置为1024,每个epoch随机处理所有训练帧。
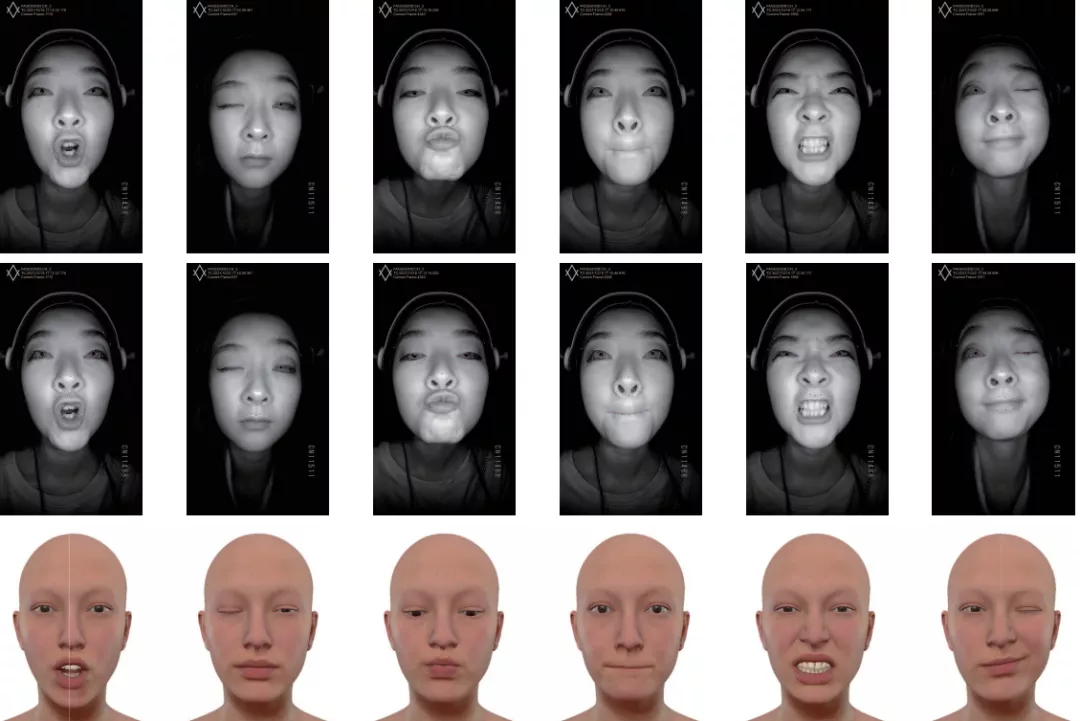
三行图片分别展示了原始表情,标了红色2d landmark点的表情,和被驱动的metahuman的表情
第一行展示了一个女孩的六种表情。分别是:翘嘴,闭上右眼,撅起嘴,闭上嘴,生气,闭上左眼。第二行图像是对应的标了红色2d landmark点的表情。可以看出,这些landmark在嘴唇、眼睛、鼻子、眉毛附近都准确地标记出来,几乎没有偏差。并且该跟踪是实时的,几乎没有时间延迟。第三行是驱动的数字人的六种表情。相比第一行,发现metahuman完全还原了人的表情,而且表情也非常精致,栩栩如生。特别是,闭眼时的眼睛和嘟嘴时的嘴唇幅度几乎一样。
我们提出了自适应回归蒸馏(ARD)框架,设计的Loss函数如下:
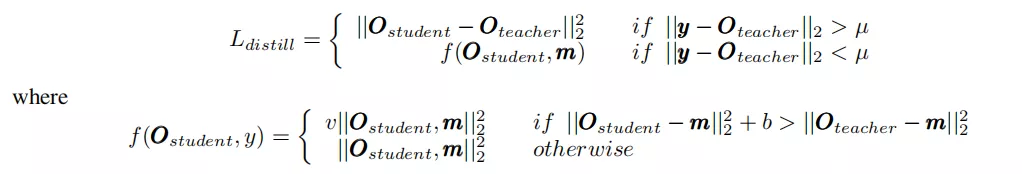
(3)
公式(3)表示:当数据点是一个异常值时,让学生从老师网络的输出值学习,而不是异常值。相反,如果不是异常点,就让学生学习真实的数据,而不是老师的“半对半错”的数据。这里,v大于1,表示当学生目前学得还不够好时,给一个更大的损失,促进学生的学习。另外,m为除了异常值外的数据集,µ为判断点是否为噪声的超参数,b为衡量教师和学生之间的表现差距,由研究者自行设定。此外,需要对几处矢量求欧几里得范数的平方。
4、实验结果
以下是自适应回归蒸馏(ARD)框架的算法伪码:

图五 混合滤波器对blendshape权重的滤波效果对比

图六 混合滤波器对landmark点的滤波效果对比
图五和图六分别展示了我们的混合滤波器对blendshape权重和landmark点的滤波效果。可以看到,混合滤波器可以有效地消除抖动,且几乎没有时间延迟。对最高值和最低值也几乎没有峰值损失。

表一 三种CPU上的处理时间
上表显示了我们的框架在三种CPU上的处理速度。可以达到70 FPS。
结论
我们使用FACEGOOD P1头戴式红外相机,避免了光线的影响和身体运动引起的剧烈抖动对视频质量的影响。在此基础上,开发了一种基于神经网络的端到端的blendshape权值输出框架,该网络可在CPU上实现70 FPS的实时计算。该方法可以将演员的表情重定向到任何3d模型。
全文完
下载链接来自互联网 仅供学习研究之用,不得用于商业,请在24小时内删除!
版权归原作者及其公司所有,如果你喜欢,请购买正版。
本站统一解压/安装密码:cgsop.com


CG模板素材网—全面收集影视资源!
www.cgsop.com
欢迎加入QQ交流群:
1群:299950416
2群:457190933
